
Nodejs is faster than Java? It's all about IO
In this post I will talk about kernel, io and all these stuff but let's start with a simple question. Nodejs is faster than Java? I've heard it a lot from my friends and from forums on the Internet. Let's make it clear, I am a big fan of Java ,specifically Java Runtime.However, I don't like Annotation driven development though.Let me explain what it means for Java to be slower.A little spoiler, it's all about IO.

Why is it slower?
Let's understand why Java is slower than NodeJs. First of all what do we mean by saying that one language is slower than another. Well language itself can't be fast, speed depends on the runtime. In this blog I will talk about Hotspot and OpenJdk runtime which implies that Java's runtime includes interpeter and two JIT compilers. Usually people talk about how fast a language could perform a CPU intensive task. Something like matrix multiplication or finding n-th number in Fibonacci sequence. In this case Java(Hotspot) beats Nodejs and even c++ (sometimes).Why ? Because of JIT. Java is a compiled language, it is compiled into a specific language called bytecode. JVM interprets this bytecode instruction by instruction which is of course slower than executing compiled machine code. However, JVM has two JIT compilers that periodically compile hot methods into machine specific code. For this to work , Hotspot stores statistics(in easiest case just counters) for each method,loop. Using these statistics, Compilers decide what to compile and how to optimize compiled code (Remove unused memory allocations, unloop statements and so on). I don't want to go deep in this topic because I am mainly focusing in non CPU related tasks , but if you are interested in JIT internals then you have to watch this excellent video by Douglas Hawkins.
Okay, now we know that Java is great in terms of CPU
intensive tasks
then why there are so many articles
about big companies moving to Node? I am not the first one
to tell you this, but Nodejs is faster because it
doesn't require a lot of user level threads(the ones that
you create by using new Thread(runnable)) in
order to provide a high performance backend server. You
probably heard
that Node js is a single threaded and it uses the technique
called Event Loop in order to handle all incoming requests.
If you are a Java developer then you probably think "What
the
hell, one thread?".
Yes, this question bothered me for a long time .As I said
before , I am a Java developer.I got used to thinking about
concurrency in terms of Thread Pools. And when someone tells
me
that
a backend server could have only one thread and still
perform
better than thread pools I just laughed at them. But really,
one thread ?
How one thread can handle all the traffic. Let's go deeper
and understand what an Event Loop is.
Event Loop
Let's look at this picture that I sincerely borrowed from Internet
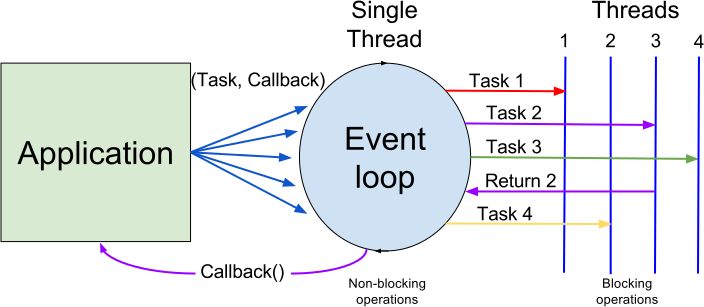
We have incoming requests and one thread that handles them, if a task is heavy(takes a lot of time) then we assign it to some sort of thread pool and create a callback ,otherwise , the event loop will be blocked, and we won't be able to handle new connections. When the task is finished , the thread pool puts a result of this task back to the event loop , then the event loop will eventually execute this callback and return the result to client . Please check out this wonderful talk byPhilip Roberts .
Now the tricky question, Ok event loop, but can't we use it in Java ? We can indeed ,moreover Servlet containers such as Tomcat use Event Loop by default. What? Yes, the default connector for Tomcat is based on Java nio which has its own event loop under the hood. Ok , if even Tomcat can do it then what is the purpose of Node? Let's now switch to Tomcat(I chose Tomcat but other servlet containers have the same principles)
Tomcat
How Tomcat NIO Connector works. First of all we can specify the amount of event loop threads that will handle incoming requests (According to my experience, one thread will be enough). After that, when connection with the client has been established, the event loop puts a task into a queue which is monitored by a thread pool of worker threads.Thread pool takes a task from the queue and assigns a worker thread to it. All application logic (Methods inside your Controllers in Spring) is executed using these threads. The problem here is that application logic usually needs to do some IO tasks such as calling cache service, sending requests to database, making Http calls to other services and so on. In most cases, these requests will block worker thread. When a worker thread is waiting for the Database to respond it doesn't do anything , as a result, if all worker threads are waiting on IO, then Tomcat can't process new tasks from the event loop. The only solution for Servlet containers prior to Servlet 3.1 specification was to increase amount of worker threads, but again , most of them won't do anything but wait for IO (BTW I want to write another small blog about Async servlets, because I have seen how developers , including me, blindly move all application logic from worker threads to async servlets without noticing that it doesn't solve problem of blocking).
Ok, finally the question that I asked myself so many times, how in the hell nodejs uses threads without blocking them, and I want to brag myself, I found the answer.
Kernel is the only source of truth
You see, NodeJs and Java are just languages, they don't
know how to write data to disk , or how to read it.They
don't even know how to
create new threads. They don't, but Kernel does. What is
Kernel ? First of all, I will explain how it works in Linux
because I have no clue what Mac and Windows do(honestly, I
am just not interested). Kernel is a heart of Linux. It's a
layer between user processes and hardware. User processes
are not allowed to work with Hardware. Then how can we
read/write from a file? Fairly simple, Kernel provides a
public API called system
calls. User processes use
these "system calls" and Kernel will do what it is supposed
to do. When we write a program(unless writing your own OS)
using any programming
language, we create a user process ,consequently, our
program will use system
calls as well. How to check it? Let's write a small Java
program
that reads a file called input.txt.This file contains only
two words Hello world
public class Main {
public static void main(String[] args){
Files.readAllBytes(Paths.get("input.txt"));
}
}
In order to see system calls we can use cli program called
strace
. Here is an example(I use Java 11 so no need to compile
java file)
strace java Main.java. The output will be huge
but we are interested in the last lines. One of them will
look like this
read(3, "\177ELF\2\1\1\0\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0p>\0\0\0\0\0\0"..., 832) = 832
Now we know that InputStream uses a system method called
read
,however read takes a file descriptor(in my case it was
number 3) created by
openat
, let's check the
manual for openat man openat. You will notice
that openat creates a blocking file
descriptor by default.It means that user thread that uses
file descriptor created by openat will have to wait for a
response
from the kernel, in other words, thread will be blocked.
Every subclass of Java's InoutStream and OutputStream uses a
blocking system calls like this one.
File Descriptors
Remember when I told you about event loop handling incoming requests ? What it really does is it creates a file descriptor for each socket connection . In Unix systems everything is a file, including sockets. OS creates a unique number called file descriptor and uses it as a file identifier(system calls such as read and write take file descriptor in order to understand from what file to read or write to). Technically , there is no limit on amount of file descriptors, you can open as much as 10K file descriptors in parallel , the only obstacle is RAM, because each file descriptor is an internal structure that occupies some memory (Now you can understand how nginx is able to handle 10K parallel requests, it uses file descriptors).
Epoll
The way Tomcat's Nio Connector works is approximately the
same as Event loop from Nodejs. Then why Node is faster.The
tricky
part is , NodeJs doesn't use blocking calls. Of course, you
can do it , but it's considered as antipattern. Worker
threads of Nodejs don't have to wait for IO and therefore
use CPU more efficiently than blocked threads from servlet
container.In order to
implement an event loop ,nodejs uses a C++ library
called
libuv, this library is a cross platform, but in Linux it
uses
a system call known as epoll.
Again , you can check the manual page related to epoll but
here I will give you a brief explanation on how it works.
Epoll is a system call that allows us to monitor sockets
for a new data. When we use epoll, our program doesn't have
to
wait until new data will appear.As soon as data from sockets
is ready, Kernel will return a list of file descriptors
associated with these sockets. Here is a
brief example on C
//create epoll
int epoll_fd = epoll_create1(0);
//event loop
while(running)
{
printf("\nPolling for input...\n");
//ask kernel which file descriptors have a new data
//The last argument is the amount of milliseconds to wait
event_count = epoll_wait(epoll_fd, events, MAX_EVENTS, 30000);
printf("%d ready events\n", event_count);
for(i = 0; i < event_count; i++)
{
//work with available data
...
}
}
Event loop asks
kernel if any sockets have a new data, if so then
we can get these data using file descriptor number , if no
sockets
have new data, then
kernel returns 0 and
main thread doesn't have to wait
.Also we have a for loop that works with data,
in this
loop we can assign heavy tasks to some sort of thread pool
because we don't want to block the main thread. When a task
is
completed we can send a response to a socket using a file
descriptor(remember, it's just an id). Under the
hood , all event loop
based servers use
these system calls in order to provide non blocking
behavior.
Just for the comparison with Java's program that reads a
file, let's write the same program using
Node.js and execute it using strace
fs = require('fs')
fs.readFile('read.txt', 'utf8', function (err,data) {
console.log(data)
});
Again the output from strace is huge but as in C code we are looking for the following system calls
- epoll_create that creates an unblocking file descriptor.
In my case it looks like this
epoll_create1(EPOLL_CLOEXEC) = 13as you can see File descriptor 13 was created - epoll_wait to wait for events from kernel.
epoll_wait(13, [{EPOLLIN, {u32=16, u64=16}}], 1024, 8100) = 1.The last argument is the time to wait for a response.
Java NIO and Netty
Starting from Java 5, we have a new package named NIO. Java
Nio gives us an API to use non blocking system
calls . So, we have a NIO package, could
we improve the servlet problem described above where most
worker threads are waiting on blocking system calls ? The
answer is, it depends. Java is an old language and as I said
before,
if you use InputStream class , then your
threads
will be blocked and I assure you ,you do, the majority of
Java
libraries use this old class from Java 1. Moreover, JDBC API
uses
blocking sockets, so all interactions with databases from
Java will be blocking. There are some projects aimed at
rewriting JDBC in order to use non blocking sockets.
The one that I contribute to and most interested in is
r2dbc. With
this library we can send non blocking requests to Database
and get a
response in the form of Reactive interfaces(Mono or Flux).
However, I want to mention that Java ecosystem is huge , and
there are a lot of frameworks that don't implement servlet
specification. My favorite one is Vert.x. It resembles a
Nodejs cause its based on exactly the same algorithms but
it uses
Java Runtime(in reality , you can use Vert.x with
JavaScript, if you are interested check the docs). It's
creator ,Tim Fox wanted to bring a
powerful , Reactive framework to Java world and I assure you
he did indeed.
Some words about project Reactor
One of the newest trends in Java backend development is a project called Reactive Spring and Project Reactor. Now, as you know the main disadvantage of servlets and blocking streams, it's easy to understand what this project tries to solve. It provides a functional API to write a non blocking backend (of course there are more things such as back pressure, but the core idea is that code must be non blocking).
Conclusion
I hope that my explanation was clear enough. I spend an enormous amount of time in order to understand how it really works and I want to thank Eli Bendersky for his wonderful blog with detailed explanation on concurrent servers and I want to recommend a wonderful book called The Linux Programming Interface . If you are interested in Kernel and system calls it has, then you will find all answers in this book.