
Project Loom. How are virtual threads different ?
I want to start this year with a blog post about Project Loom , a new JEP from Oracle that will bring virtual threads(or coroutines) to the JVM. That's huge and people have been waiting for it for ages. Right now, Java ecosystem provides few frameworks to work with sockets in non-blocking way such as Project Reactor. I have nothing against of Reactor project, Confluence made a good developer experience for regular devs to use non-blocking API, however there is a big drawback in Reactor that I see. Once you start writing a backend in a reactive style, you can't stop. All blocking calls have to be rewritten using non-blocking API which is a completely new coding style with its own hidden surprises. Of course, all blocking calls can be delegated to dedicated Thread Poll but in this case we are going back to standard thread per request model . But this blog post is not about Reactor, it's about Loom. I spend quite a lot of time trying to understand what Oracle means by saying "Virtual Threads" and how it can solve the problems we face using Servlet API(Spring MVC). And after endless time of reading mailing lists and trying Loom in my local machine I think I finally got it. Before I start, all opinions here are my own and can(probably are) be wrong, always double check by your own and if you see any mistakes please let me know so this blog can become better. And so Let's start

The current state of blocking IO
Let's talk about a regular Java backend. You want to write some service that solves a particular business problem. You generate a new Spring boot project that uses Tomcat under the hood, then you create a database schema and use Hibernate as an ORM solution but instead of working with EntityManager directly you delegate the heavy work to Spring Data, and lastly there are probably some other networking services involved so your backend is making http requests to generate email, make a payment and so on. That's a typical Java based backend, and we all are familiar with how it works.
Under the hood Tomcat uses non-blocking event loop based
thread that accepts new connections from users, then it
delegates them into a fixed size thread poll that executes a
business logic. Business logic almost always contains an IO
interaction with remote services such as
cache(Redis,Memcached),database(Postgres),
and third party services(Stripe). Most of the time ,the
networking communication
logic is written in the blocking way whether it's RestTemplate
to send an http request to the service
or JdbcTemplate to fetch some data from the
database. Blocking calls will block a
thread from Tomcat's thread pool and the only way to
increase the throughput of the backend is to increase the
amount of threads in the poll.
Increasing amount of threads means more context
switching(which is actually fast enough in latests Linux
kernels which use
a fair scheduler) and more memory usage because each
thread needs a memory for a stacktrace(this value varies but
for my Ubuntu 20.04 it's 8Mb per thread you can check stack
trace size by running ulimit -s in your shell).
As you can see,
increasing amount of threads isn't scalable, so to solve a
throughput problem we can use asynchronous style to work
with sockets.
The blocking IO in java is represented by two main classes
namely InputStream and
OutputStream and their subclasses. Let's say we
want to read some data from database using Jdbc, the
stacktrace of the program will end up by calling the
read method of InputStream, here
is the interface for this method.
abstract class InputStream implements Closeable {
//Reads the next byte of data from the input stream
public abstract int read() throws IOException;
}
Remember, read doesn't specify how it should be
implemented , it just tells you that it will return data
from the stream. It didn't satisfy my curiosity so I used
strace(cli application that keeps track of the
system calls your program is making) to see what my Linux
machine is actually
doing when read is called. So let's say we have
a simple program that reads file's content
public class TestInputStream{
public static void main(final String[] args) {
var body = Files.readAllBytes(Path.of("test.txt"));
}
readAllBytes uses
InputStream#read() under the hood. Next step is
to compile this java file by using javac
Main.java, lastly run this command in your
shell
strace -o output.txt -f ./bin/java Main.
All system calls that Main.java uses were saved into the
output.txt
file. If you open the file, output will be huge because
strace also tracked all syscalls that JVM uses upon
starting, but I want you to focus on those few lines
43338 openat(AT_FDCWD, "test.txt", O_RDONLY) = 4
43338 read(4, "\0\0\0\30ftypmp42\0\0\0\0isommp42\0\22\321\354moov"..., 75391864) = 75391864
43338 close(4) = 0
Let's go over the syscalls line by line
- First we call
openatto open the file , the method returns a file descriptor(number 4 in this case), a number that can be used to find this particular file in the filesystem - Next we read the content of the file by given file descriptor
- Lastly we release file descriptor back to OS, because
amount of file descriptors is limited, you must give
them back once you are done working with a file(or
socket, that's basically why we have
try/finallyblock in java, to efficiently release file descriptors or other resources we don't need anymore)
The main syscall here is read that accepts 3
parameters
- fd - file descriptor
- buf - byte array where the content will be saved
- count - amount of bytes we want to read
Reading the manual page for read call , I
didn't
find any references to blocking an underlying user Thread,
so
I started googling and found this article from LWN.net. The
quote from this blog states
So a call to read() on a normal file descriptor can always block; most of the time this blocking causes no difficulties, but it can be problematic for programs that need to always be responsive
Now we know the problem, InputStream is using
blocking system calls to read the data by file descriptor.
How is it relevant to our backend service ? Well, when you
make a networking call to the database or to another
service, Linux will use socket syscall that
creates a file descriptor for the socket, the
read method then will read data from the
incoming traffic by using this file descriptor in the same
blocking manner. I think you got an idea, to make
non-blocking reads we need to use another syscall
Meet epoll
I already talked about epoll in my previous blog
where I compared Java
with Node js but I didn't show how it can be used
within the Java code. Let's see an example by writing a
small program that downloads a video from youtube in
non-blocking way using async-http-client.
Here is the code
public static void main(String[] args) {
try (final AsyncHttpClient client = Dsl.asyncHttpClient()) {
client
.prepareGet("use_any_youtube_link")
.execute()
.toCompletableFuture()
.thenAccept(response -> {
final byte[] responseBody = response.getResponseBodyAsBytes();
Files.write(Path.of("test.mp4"), responseBody);
})
.thenAccept(unused -> System.out.println("Done"))
.join();
}
In essence, we are making a http call that returns a CompletableFuture(java's
way to define a Promise), then we block the main thread by
calling join. Let's see what strace can tell us
about this code(you can find complete code sample here.
Here is the output I got.
epoll_create1(EPOLL_CLOEXEC) = 20
eventfd2(0, 0) = 23
epoll_ctl(22, EPOLL_CTL_ADD, 23, {EPOLLIN, {u32=23, u64=140381006069783}}) = 0
epoll_wait(20,...)
A lot of new syscalls , let's walk through each of them
epoll_create1- creates an instance of epoll, in this case kernel create an epoll with id 20eventfd2- creates a file descriptor for event notification, in this case the fd is 23epoll_ctl- tell the kernel file descriptors you’re interested in updates about, we are interested in fd 23epoll_wait- wait for updates about the list of file descriptors you’re interested in
Just a reminder, Linux kernel is written in C so the C equivalent of this program would look like this
int epollfd = epoll_create1(0);
epoll_ctl(epollfd, EPOLL_CTL_ADD, listener_sockfd, &accept_event)
while (1) {
int number_fd_ready = epoll_wait(epollfd, events, MAXFDS, -1);
//some logic to work with these file descriptors
}
As you can see, the C version has single thread that fetches
available file descriptors in the infinite loop(event loop)
without blocking an underlying
thread. Kernel does all the heavy work for us. async-http-client
did a great job
of giving us
an abstraction over epoll, but still , most developers are
not familiar with this programming style, moreover, writing
your code in sequential manner is a way easier than working
with callbacks and Features. Here comes the
first problem that Project Loom tries to solve, namely,
allow Java
developers to write asynchronous code in sequential way.
Legacy software can't take advantage of Async API
Ok, let's say you know how to write efficient code using
asynchronous style, and you are willing to start your new
startup with something like Project Reactor , great but keep
in mind, Java is old and most Java based backends were
written in a blocking way. Servlet API that uses thread
per-request model, Hibernate that uses JDBC under the hood
while
JDBC is using blocking InputStream to read the
data from a wire. Wouldn't it be nice if JVM runtime could
detect all blocking calls and replace them with async epoll
? This is exactly what Golang did by using goroutines. Here
is an example of http request written in Go
func main() {
resp, err := http.Get("https://example.com/")
defer resp.Body.Close()
}
It's similar to http request you would do with RestTemplate,
the only difference is , RestTemplate uses
read syscall while go uses epoll.
Go doesn't force you to write your code with async callbacks
in mind, the runtime is smart enough to detect(when
possible) syscalls that
block your thread and replace them with async equivalents.
Meet Project Loom
Project loom is an attempt from Oracle to make JVM runtime smarter by introducing what is called Virtual Threads. I personally found this expression a little vague. In reality , with Project Loom, JVM runtime will replace all blocking calls with non-blocking equivalents the same way as Golang does. You don't have to replace your Servlet API with Project Reactor to use async sockets if jvm runtime can do it for you. Here is a small example(the source code is available here) that shows you how Project Loom is going to work.
private record URLData(URL url, byte[] response) { }
private URLData getURL(URL url) throws IOException {
try (final InputStream in = url.openStream()) {
return new URLData(url, in.readAllBytes());
}
byte[] retrieveURL(URL url) throws Exception {
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
final Callable<URLData> callable = () -> getURL(url);
return executor.submit(callable).get().response;
}
}
Next we need to compile it using Loom build of open-jdk(You
can
download it from here) with
experimental features enabled
flag javac --enable-preview --release 19
LoomTest.java, finally let's run it in background
mode and save thread dumps
java --enable-preview LoomTest & echo $!
[1] 65371
jcmd 65371 JavaThread.dump threads.txt
cat threads.txt
java.base/sun.nio.ch.EPoll.wait(Native Method)
java.base/sun.nio.ch.EPollPoller.poll(EPollPoller.java:70)
java.base/jdk.internal.vm.Continuation.yield(Continuation.java:407)
java.base/java.lang.VirtualThread.yieldContinuation(VirtualThread.java:351)
java.base/sun.nio.ch.NioSocketImpl.park(NioSocketImpl.java:181)
java.base/java.net.URL.openStream(URL.java:1163)
LoomTest.getURL(LoomTest.java:22)
Some things to notice
- JVM didn't use
readmethod of InputStream - JVM replaced an actual socket implementation with an async one from Java-Nio package
EPoll.waitmethod was used which just usesepoll_waitsyscall
This is what Project Loom is all about. Instead of rewriting
Java programs using a new programming paradigm, developers
could just use virtual threads and JVM runtime will replace
all blocking calls with non-blocking ones. There are also
some changes in JDK standard library code, for example, all
children of Input/Output streams were rewritten to
eliminate synchronized keyword because it
generates an assembly which doesn't allow kernel to use
epoll(I am not sure why, haven't worked with assembly yet).
What about Servlet Containers?
Most Java servers are written using ServerSocket
class that simply listens for new connections in given port.
Here is the small example how you can implement a http
server using thread per request model
try (var serverSocket = new ServerSocket(8080)) {
try (var pool = Executors.newFixedThreadPool(10)) {
while (true) {
Socket connectionSocket = serverSocket.accept();
pool.submit(() -> {
InputStream inputToServer = connectionSocket.getInputStream();
OutputStream outputFromServer = connectionSocket.getOutputStream();
Scanner scanner = new Scanner(inputToServer, StandardCharsets.UTF_8);
PrintWriter serverPrintOut = new PrintWriter(new OutputStreamWriter(outputFromServer, "UTF-8"), true);
while (scanner.hasNextLine()) { String userData = scanner.nextLine();}
User creates a connection, server submits this task into
dedicated pool. As you can see we are using InputStream
to read the data from the user. The read method is blocking
as I said before so Thread from a pool can't do anything
else while waiting for user to finish the input.But what if
we change the pool into a virtual one(here is the source
code) ? var pool =
Executors.newVirtualThreadPool(10)
In this case, JVM runtime will switch to non-blocking sockets without you changing any lines of code(except for the Executor implementation). If you run this server and load test it with a bunch of telnet clients, there will be only one thread that handles the IO part. Here is the view from JVisualVM after opening 3 telnet sessions to the server
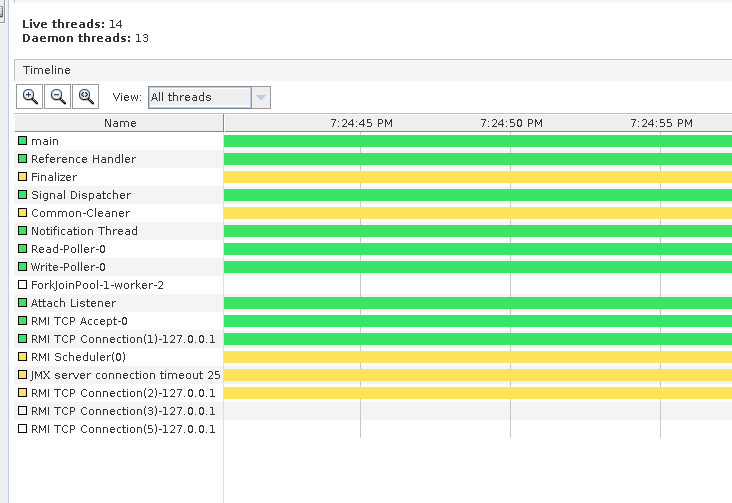
Read and write poller are epoll related
threads, all logic is running within Main
thread without using any additional threads
Finale
I hope it was an interesting read for you, and now you have a better understanding of what virtual threads are actually meant to be and how it works internally in syscalls levels. Cheers !